En los últimos años, se ha evidenciado una gran aceleración en la creación de datos para todo tipo de negocio, lo que ha generado la necesidad de evolución en los procesos para el análisis documental.
En muchos casos se tendrá la información estructurada, pero en otros podrían ser documentos de texto, como contratos e informes, en los cuales un análisis convencional requiere una persona que lo lea e interprete, lo que conlleva un desgaste de tiempo y una cobertura limitada.
Para ello, modelos de Machine Learning que clasifiquen y estructuren los documentos, junto a otros que identifiquen aspectos relevantes y extraigan parámetros de interés, permitirán incrementar exponencialmente la eficiencia en el análisis documental.
Esta eficiencia beneficia diferentes áreas de negocio, pudiendo ser jurídicas, contables, de análisis, de auditoría u otras que donde sea necesario el análisis documental; abriendo la posibilidad de ejecutar planes de acción o identificar exposición a riesgos del negocio de manera más rápida y efectiva.
Incluso, las funcionalidades de estos modelos podrían expandirse a otros procesos, como son la migración masiva y ordenada de documentos entre aplicativos, apoyados con procesos de descubrimiento y análisis de información o creación de sistemas de búsqueda.
Un poco de la construcción
La construcción de estos modelos se basa principalmente en diferentes técnicas de:
- Identificación y extracción morfológica (raíces y unidades léxicas),
- Sintáctica (estructuras gramaticales).
- Semántica (significado de las palabras y expresiones).
Junto a estas técnicas también se establecen reglas de negocio que precisan la identificación dentro del texto, de su estructura y de aspectos de interés.
Adicionalmente se pueden tener procesos de comparación que miden la similitud entre textos.
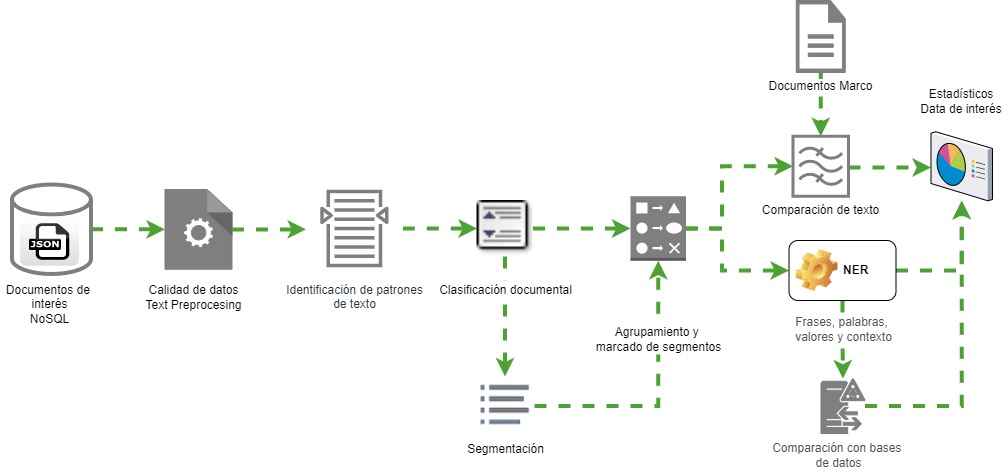
En el entrenamiento inicial es importante definir las reglas de negocio que permitirá principalmente dos cosas:
- La primera, identificar qué documento se está procesando, ¿es un contrato, un informe u otro tipo de documento?
- La segunda, identificar que dicho documento se pueda estructurar, por ejemplo, un contrato comúnmente se puede estructurar debido a que contiene elementos como cláusulas y parágrafos, los cuales se podrían extraer de manera individual, así mismo como un título con número de contrato que permitiría establecer su identificación y tipología.
Definidas las reglas para cada tipo documental y las técnicas de identificación y extracción, se debe realizar ajustes a la sensibilidad del modelo, tomando en cuenta los errores humanos al momento de redacción del documento, evitando, que algún tipo de error ortográfico o diferencias en la estructura para un mismo tipo documental descarte el documento del modelo.
Ya con modelos de machine learning se retroalimentara y ajustaran las diferentes técnicas utilizadas, reduciendo la cantidad de falsos positivos y aumentando la cobertura de documentos.
Los procesos de comparación se encargarán de identificar atipicidades entre documentos, ya sea de manera general o en segmentos específicos, como por ejemplo comparar una misma cláusula en diferentes contratos, para identificar si en estas pudiera presentarse una atipicidad con respecto a las otras.
A su vez, los procesos de comparación apoyarán la retroalimentación del modelo identificando documentos mal clasificados, que podría ser aquellos a los que su porcentaje de similitud con respecto a los documentos del mismo tipo es muy bajo o en caso contrario para aquellos documentos no clasificados inicialmente, pero que presentan un porcentaje de similitud considerable con respecto a un tipo ya establecido.
Ahora los resultados, ¿es buena técnica para el análisis documental?
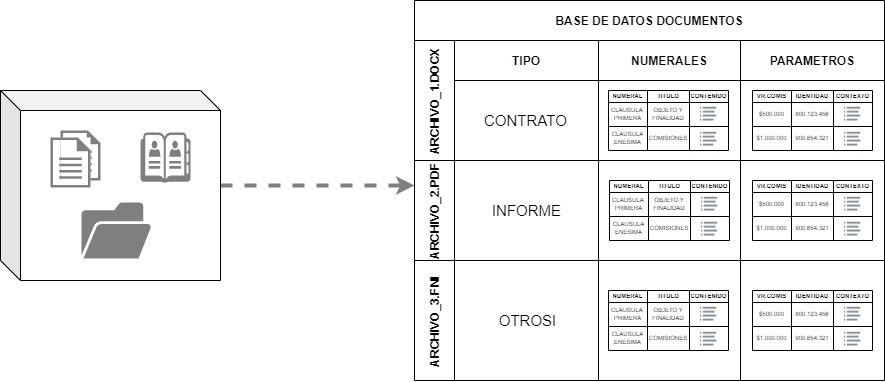
Aplicando estos modelos se pasa de tener una cantidad de archivos desordenados, ya sean físicos o digitales y pudiendo estar en carpetas o en aplicativos, a consolidarla en una sola base de datos.
Allí están todos estos documentos segmentados, cada uno con su contenido y tipología, permitiendo ya de esta manera el relacionamiento a otra información estructurada que brinde mayores detalles del negocio o del archivo.
Desde este punto la cantidad de análisis aplicables se incrementa considerablemente, así como el valor que puede generar tener esta información disponible para los equipos que realizarán el análisis posterior.
En el equipo STRADATA, se cuenta con el conocimiento de estas técnicas y modelos, que ya han permitido obtener resultados valiosos para nuestros clientes.
También hemos podido evidenciar el incremento de eficiencia, productividad y además han generado la posibilidad de creación de nuevos análisis para los negocios, aumentos exponenciales en las coberturas y mejoras en las metodologías de trabajo.
Con esto presente, las nuevas tecnologías aplicadas al análisis documental representan una evolución y ventaja competitiva para el negocio en general.
Autor: J. Ramírez



